This notebook demonstrates how DimensionInterval enables automatic cross-slicing between multiple interval types over a shared continuous dimension.
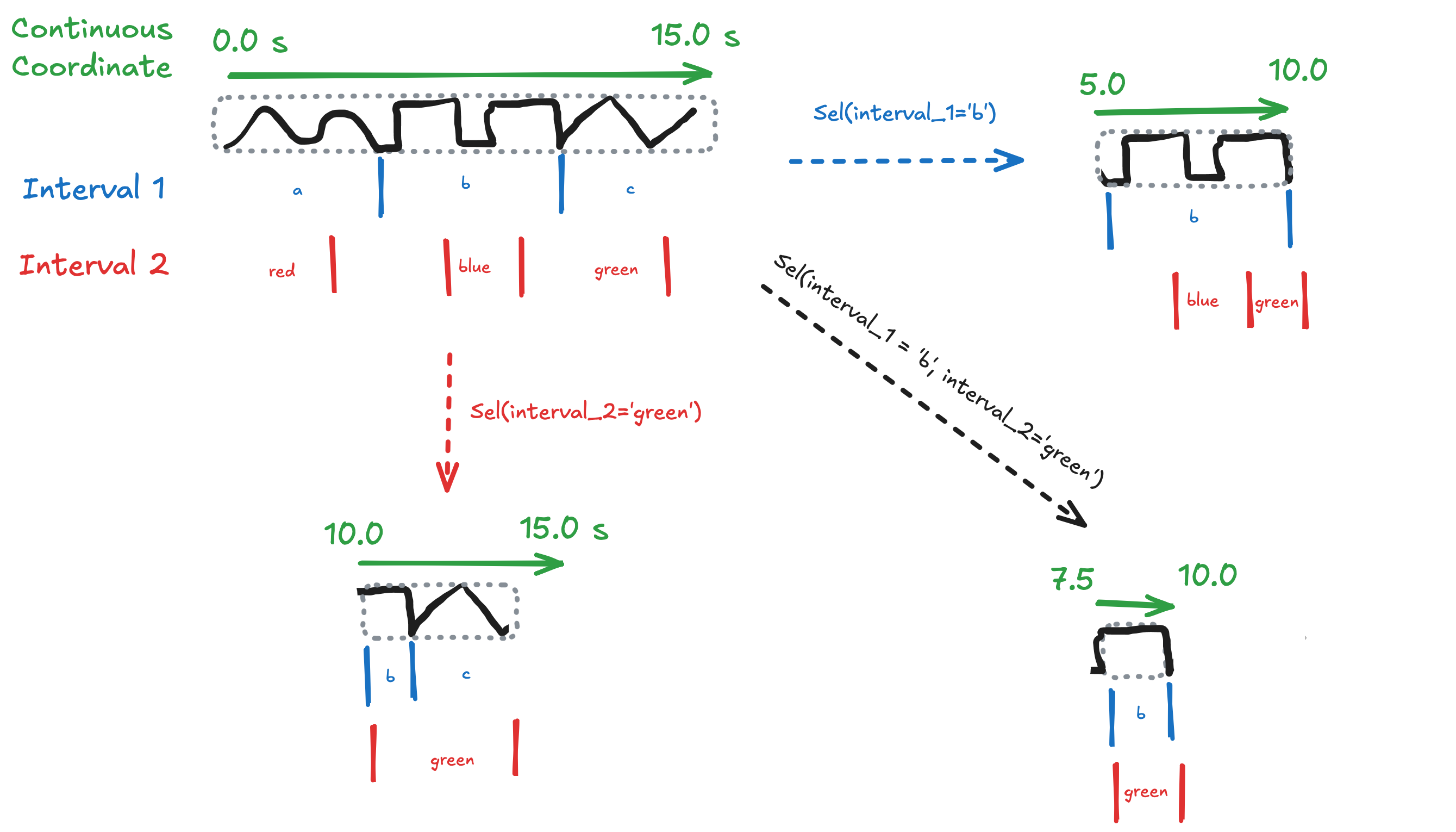
When you select a specific word, you want the time and phoneme dimensions to automatically constrain to only the overlapping values. This is exactly what DimensionInterval provides.
import numpy as np
import pandas as pd
import xarray as xr
from linked_indices import DimensionIntervalUse Case: Speech Data¶
Imagine you have speech data with:
A continuous time dimension (e.g., audio samples at regular intervals)
Word intervals - each word spans a range of time
Phoneme intervals - each phoneme spans a smaller range of time within words
Creating the Dataset¶
First, let’s create a dataset with:
1000 time points from 0 to 120
3 words: “run” [0-40), “quickly” [40-80), “home” [80-120)
6 phonemes, each spanning 20 time units
Part of speech labels for each word (verb, adverb, noun)
Note that word intervals are larger and contain multiple phoneme intervals.
This example uses pd.IntervalIndex directly. For an alternative approach using onset/duration coordinates, see the Onset/Duration Example.
C = 2 # number of channels
N = 1000 # number of time points
times = np.linspace(0, 120, N)
# Word intervals - 3 words covering full time range
word_breaks = [0.0, 40.0, 80.0, 120.0]
word_intervals = pd.IntervalIndex.from_breaks(word_breaks, closed="left")
word_labels = ["run", "quickly", "home"]
word_pos = ["verb", "adverb", "noun"] # part of speech labels
# Phoneme intervals - 6 phonemes, each 20 units
phoneme_breaks = [0.0, 20.0, 40.0, 60.0, 80.0, 100.0, 120.0]
phoneme_intervals = pd.IntervalIndex.from_breaks(phoneme_breaks, closed="left")
phoneme_labels = ["ah", "ee", "oh", "oo", "eh", "ih"]
data = np.random.rand(C, N)
# Create the dataset
ds = xr.Dataset(
{"data": (("C", "time"), data)},
coords={
"time": times,
"word_intervals": ("word", word_intervals),
"word": ("word", word_labels),
"part_of_speech": ("word", word_pos),
"phoneme_intervals": ("phoneme", phoneme_intervals),
"phoneme": ("phoneme", phoneme_labels),
},
)
dsApplying the Multi-Interval Index¶
Now we apply DimensionInterval to link all these coordinates together. This replaces the default indexes with a single custom index that understands the relationships between time, words, and phonemes.
ds = ds.drop_indexes(["time", "word", "phoneme"]).set_xindex(
[
"time",
"word_intervals",
"phoneme_intervals",
"word",
"part_of_speech",
"phoneme",
],
DimensionInterval,
)
dsNotice in the Indexes section that all coordinates are now grouped under a single DimensionInterval index. This means selections on any of these coordinates will automatically propagate constraints to the others.
ds.xindexesThe raw data of the intervals are directly encoded in the dataset so we can trivially retrieve them
ds["word_intervals"]It’s possible to make multiple selections on metadata at the same time
ds.sel(part_of_speech="adverb", phoneme="oh")Cross-Slicing: Selecting on Time¶
When we select a time range, both word and phoneme dimensions are automatically constrained to only include intervals that overlap with that time range.
# Time 30-70 overlaps:
# - word: [0,40), [40,80) -> 2 words
# - phoneme: [20,40), [40,60), [60,80) -> 3 phonemes
ds.sel(time=slice(30, 70))Cross-Slicing: Selecting on Word Interval¶
Selecting a point within a word interval selects that word and constrains time and phonemes accordingly.
# Selecting at time=60 picks the word interval [40,80) which is "quickly"
# This constrains:
# - time to 40-80
# - phoneme to [40,60), [60,80) -> 2 phonemes
ds.sel(word_intervals=60)Cross-Slicing: Selecting on Phoneme Interval¶
Similarly, selecting a phoneme constrains time and words.
# Selecting at time=70 picks phoneme interval [60,80)
# This constrains:
# - time to 60-80
# - word to [40,80) -> 1 word ("quickly")
ds.sel(phoneme_intervals=70)isel¶
You can isel on any of the dimension coords. In this case time, word, phoneme
This means you can easily perform meaningful selections such as give me the second word that was spoken.
ds.isel(word=1)or more complex ones such as the 2nd phoneme of the 3rd word
ds.isel(word=2).isel(phoneme=1)Summary¶
DimensionInterval provides:
Automatic cross-slicing - Select on any dimension and all others are constrained appropriately
Multiple interval types - Support for multiple interval dimensions (words, phonemes, etc.) over a single continuous dimension
Multiple labels per interval - Each interval dimension can have multiple label coordinates (e.g., word text and part of speech)
Flexible selection - Use
sel()with time values, interval coordinates, or label coordinates
This is particularly useful for:
Speech/audio data with hierarchical annotations
Time series with multiple granularities of events
Any data where intervals at different scales need to stay synchronized